
Minesweeper reinforcement learning
Remember the legendary Minesweeper?
Well, I thought that it would be cool to write a program that can play Minesweeper. And then I thought: I don’t want to think hard about writing such program. This game usually requires a fair amount of thinking e.g., lots of probabilities and considering multiple scenarios at once. It is fairly complex, and even though I can sometimes do that subconsciously in my head, it is too much work to examine my automatic thinking, let alone replicate it in code. Also if we do it that way, where is the fun? Instead, let’s just leave it to the computer to figure out how to best play Minesweeper. In other words, this is not a Minesweeper solver. This is a program that generates a solver by playing the game on its own and figuring out how best to win. It is just easier this way.
Why this is easier than many other games
This concept of programs playing games and learning on their own is called reinforcement learning (RL). Great feats have been accomplished in this field including, for example, creating a Dota 2 AI that beat the top human players. Now, I should make it clear that Minesweeper is, from a reinforcement learning perspective, a very simple game. For starters, there is only one player, and the logic of the game is very straightfoward: avoid clicking a bomb until you have clicked all non-bombs. In addition, when considering whether or not to click a certain square, you only need to consider its local neighbourhood, instead of the whole map. Finally, the game can safely be played in a “greedy” way. In general terms, this means that to solve a game, it is okay to favor short-term fullfillment, because short-term fullfillment leads to long-term fullfillment. This is not always the case (for example: life and other complex games). But in Minesweeper, this is the case: clicking any square that you know is not a bomb will bring you closer to solving the puzzle, and cannot hurt you in the future. This will turn out to be a huge factor in how simple our reinforcement learning approach can be.
First, let’s make a Minesweeper game
Implementing a Minesweeper game is fairly simple. My implementation uses a few arrays, simple logic, and a Pandas dataframe to make it look nice. You can see it in action below:
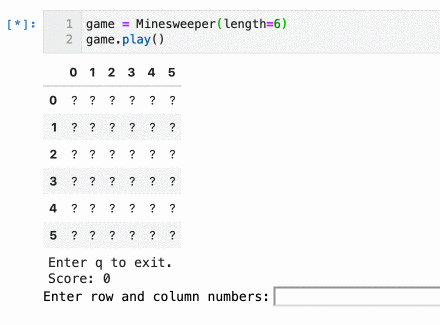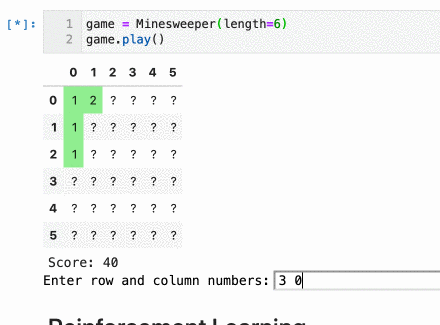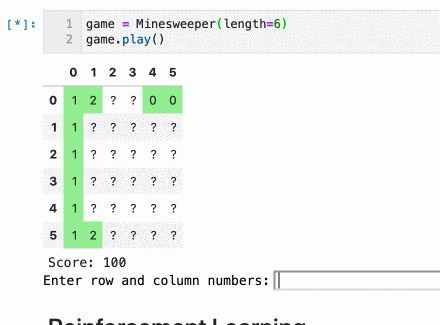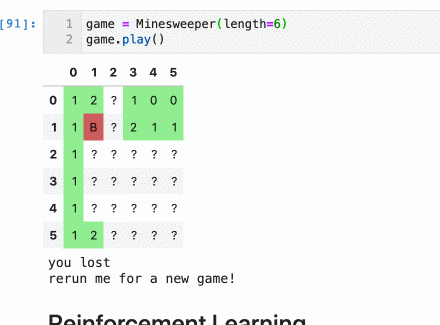
You can play (or edit) the game by running the Jupyter notebook on Binder here
Note that if a bomb is clicked, the player receives reward of -10 points and the game ends. If a non-bomb is clicked, the reward is +10 and the game continues.
Problem formulation
Now let’s make a simple reinforcement leaning method. Our method works by considering every square in the game and considering its neighbourhood (a window of a certain size centered around that square). It then clicks the one that it thinks is least likely to have a bomb. At first, nothing is known about the squares and their neighbourhood, and so it acts purely randomly. However, over time, it starts to calculate an expected reward value for each possible neighbourhood. To demonstrate this, let’s consider the following neighbourhood:
? ? ?
? S ?
? 0 ?
Since the square under consideration (marked S) is right next to a square with the value “0”, it cannot be a bomb. Our method won’t know that at first, but as it encounters this neighbourhood over and over, it will realize that it consistently gives a reward of +10, and thus will have an expected reward value of +10.
Now contrast that with this neighbourhood:
? ? ?
? S ?
? 6 ?
This square is right next to one that has a “6”. This means that as our method encounters this neighbourhood, depending on its luck, it might or might not contain a bomb. This means that the expected reward value for this neighbourhood will be lower than +10. By the same logic, if a neighbourhood always contains a bomb, it will have an expected reward value of -10. Essentially, over time, our method calculates the true statistical expected value for the reward for each neighbourhood, and then it uses that information to click the best one it can find.
And it works!
Surprisingly, this method seems to work. The next shows that over time, our solver gets better and better. It also discovers new configurations of windows over time, which is the expected behaviour.

Not just that. For our game map size and difficulty level, 60% win rate is pretty on par with fancy solvers that I found on the internet.
Later, fam.
Note on Python vs Julia
I originally wrote all of the code in Python, but I switched to Julia because I was looking for better performance. Learning was 10-30x faster in Julia than in Python! If you haven’t given Julia a shot before, try it!